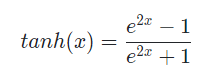[DL] 활성화 함수(Activation Function), Sigmoid/ReLU/tanh/Leaky ReLU/GELU/ELU/SoftPlus/Swish
mhiiii
2024. 12. 5. 14:17
728x90
활성화 함수란?
인공 신경망에서 입력 신호의 가중치 합을 출력 신호로 변환하는 함수
활성화함수는 비선형성(non-linearity)을 가지며,
입력에 대한 비선형 변환을 통해 신경망이 다양한 종류의 복잡한 함수를 학습할 수 있게 함
모델링할 때, 자신에게 맞는 활성함수를 잘 찾는 것이 중요
Hidden Layer
Multi-layer perceptron: ReLU 계열
Convolution neural network: ReLU 계열
Recurrent neural network: sigmoid / Tanh
Output Layer
Regression: 출력노드는 1개로 설정 + Linear activation
Binary classification: 출력노드는 1개로 설정 + Sigmoid
Multi-class classification: 출력노드는 class개수로 설정 + Softmax
1. Sigmoid
시그모이드 함수($\sigma$)는 Logistic 함수라고 불리기도 함
입력값을 0과 1 사이로 보내는 함수
분류 문제에서 많이 사용
역전파 과정에서 기울기 소실(Gradient Vanishing) 문제 발생할 수 있음 주황색 부분은 기울기를 계산하면 0에 가까운 아주 작은 값이 나오게 됨
# 시그모이드 함수 그래프를 그리는 코드
def sigmoid(x):
return 1/(1+np.exp(-x))
x = np.arange(-5.0, 5.0, 0.1)
y = sigmoid(x)
plt.plot(x, y)
plt.plot([0,0],[1.0,0.0], ':') # 가운데 점선 추가
plt.title('Sigmoid Function')
plt.show()
2. Tanh(Hyperbolic Tangent Function)
입력값을 -1과 1사이의 값으로 변환
역전파 과정에서 시그모이드 함수와 같은 문제 발생
그러나, 범위가 [0,1]에서 [-1,1]로 바뀌어 변화폭이 크기 때문에 기울기 소실 증상이 상대적으로 적음
x = np.arange(-5.0, 5.0, 0.1) # -5.0부터 5.0까지 0.1 간격 생성
y = np.tanh(x)
plt.plot(x, y)
plt.plot([0,0],[1.0,-1.0], ':')
plt.axhline(y=0, color='orange', linestyle='--')
plt.title('Tanh Function')
plt.show()
3. ReLU
ReLU함수는 기울기 소실 문제를 해결
단순 임계값(그림에서 0)을 정해 사용하기 때문에 속도 빠름
$f(x) = max(0, x)$
음수를 입력하면 0을 출력하고, 양수를 입력하면 입력값을 그대로 반환
특정 양수값에 수렴하지 않으므로 깊은 신경망에서 시그모이드 함수보다 훨씬 더 잘 작동
하지만, 음수일 때 기울기가 0이 되기 때문에 이 뉴런은 다시 회생하기 어려움, Dying ReLU
기울기는 0(x<0)과 1(x>=0)로 나눠짐
def relu(x):
return np.maximum(0, x)
x = np.arange(-5.0, 5.0, 0.1)
y = relu(x)
plt.plot(x, y)
plt.plot([0,0],[5.0,0.0], ':')
plt.title('Relu Function')
plt.show()
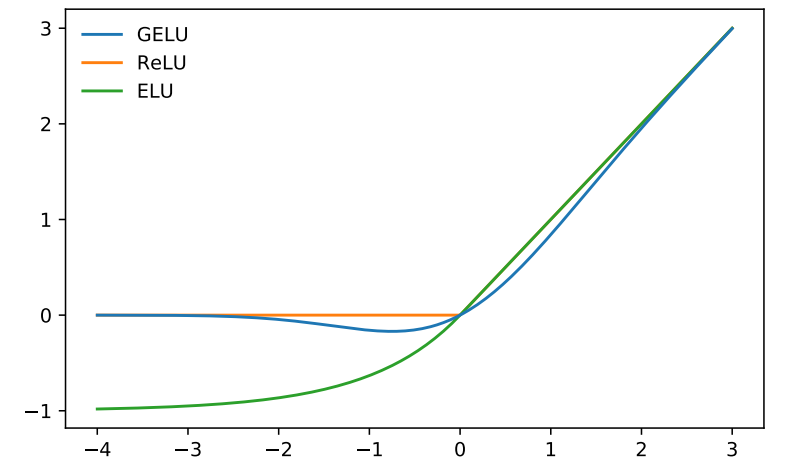
입력 값이 양수에서 음수로 변할 때에도 smooth한곡선으로 미분이 가능하고 비선형성을 더 잘 모델링
α값이 고정되어있다는 단점
7. PReLU(parametric rectified linear unit)
α가 훈련하는 동안 학습되는 방법
음수 영역의 기울기를 학습 가능한 파라미터로 정함
x가 양수이면 ReLU와 동일하게 동작
α를 모든 뉴런에 대해 공유할 수도 있고, 개별적으로 학습 가능
8. GELU (Gaussian Error Linear Unit)
$$\begin{align} f(x) & = x P ( X \leq x ) = x \Phi (x) \\ & = 0.5 x ( 1 + tanh [ \sqrt{2 / \pi} ( x + 0.044715 x ^ 3)]) \ \end{align}$$
이러한 문제를 해결하기 위해 GELU 제안됨
입력 값에 대해 표준 가우시안 누적 분포 함수를 곱하여 계산
입력 값의 크기에 따라 가중치를 부여하는 비선형성을 도입 입력 값이 크면 클수록 해당 입력에 더 큰 가중치를 부여 ( 클 수록 더 중요하다는 가정에 기반)
왜 입력값이 크면 출력값을 크게 만들까?
통계적 관점
가우시안 분포의 CDF(누적 분포 함수)Φ(x)를 사용하는 것은, 뉴런의 출력을 확률적으로 결정한다고 볼 수 있음 ( 특정 값이 정규분포 상에서 얼마나 큰지를 나타내는 확률을 계산 )
이 분포에 따르면, 큰 입력값은 더 높은 확률을 가지고 출력에 반영
GELU는 단순히 입력값의 크기(양수, 음수)에 따라 출력을 조절하는 것이 아니라, GELU를 사용하면 신경망이 데이터를 학습하면서 "실제로 어떤 입력값이 중요한지"( 어떤 입력값이 오차를 줄이는 데 중요한 역할을 하는지 확률로 )를 알아내고, 중요한 값에는 더 높은 가중치를, 덜 중요한 값에는 낮은 가중치를 부여