[DL] 기울기 소실과 폭주 (Gradient Vanishing, Exploding)
Gradient Vanishing

깊은 인공 신경망을 학습하다보면 역전파 과정에서 입력층으로 갈 수록 기울기(Gradient)가 점차적으로 작아지는 현상이 발생
입력층에 가까운 층들에서 가중치들이 업데이트가 제대로 되지 않으면 결국 최적의 모델을 찾을 수 없게 됨
Gradient Exploding
기울기가 점차 커지더니 가중치들이 비정상적으로 큰 값이 되면서 결국 발산
기울기 소실과 폭주를 막는 방법
1. 시그모이드 대신 ReLU를 사용할 것
이전에 로지스틱 회귀의 시그모이드 함수를 배우면서
입력의 절대값이 클 경우에 시그모이드 함수의 출력값이 0 또는 1에 수렴하면서 기울기가 0에 가까워진다고 배움
결국, 역전파 과정에서 전파시킬 기울기가 점차 사라져 입력층 방향으로 갈 수록 제대로 역전파가 되지 않게 됨
기울기 소실을 완화하는 가장 간단한 방법은 은닉층의 활성화 함수로 ReLU, ReLU의 변형들을 사용하는 것
2. 가중치 초기화 방법을 달리할 것
같은 모델을 훈련시키더라도 가중치가 초기에 어떤 값을 가졌느냐에 따라서 모델의 훈련 결과가 달라지기도 함
- 세이비어 초기화(Xavier Initialization)
균등 분포(Uniform Distribution) 또는 정규 분포(Normal distribution)로 초기화 할 때 두 가지 경우로 나뉨
이전 층의 뉴런 개수와 다음 층의 뉴런 개수가 필요
이전 층의 뉴런의 개수를 $n_{in}$, 다음 층의 뉴런의 개수를 $n_{out}$
균등 분포 ---------
$$W \sim Uniform(-\sqrt{\frac{6}{ {n}_{in} + {n}_{out} }}, +\sqrt{\frac{6}{ {n}_{in} + {n}_{out} }})$$
정규 분포 ---------
$$σ=\sqrt{\frac { 2 }{ { n }_{ in }+{ n }_{ out } } }$$
여러 층의 기울기 분산 사이에 균형을 맞춰서 특정 층이 너무 주목을 받거나 다른 층이 뒤쳐지는 것을 막음
주로, 시그모이드나 tanh같은 S자 형태의 활성화 함수와 잘 어울리며
ReLU와 함께 사용할 경우 성능이 좋지 못함 $\to$ He 초기화를 주로 사용 - He 초기화(He initialization)
세이비어 초기화와 유사하게 정규 분포와 균등 분포 두 가지 경우로 나뉨
다만, 세이비어 초기화와 다르게 다음 층의 뉴런의 수를 반영하지 않음
이전 층의 뉴런의 개수를 $n_{in}$
균등 분포 --------
$$W\sim Uniform(- \sqrt{\frac { 6 }{ { n }_{ in } } } , \space\space + \sqrt{\frac { 6 }{ { n }_{ in } } } )$$
정규 분포 --------
$$σ=\sqrt{\frac { 2 }{ { n }_{ in } } }$$
3. 배치 정규화
배치 정규화는 인공 신경망의 각 층에 들어가는 입력을 평균과 분산으로 정규화
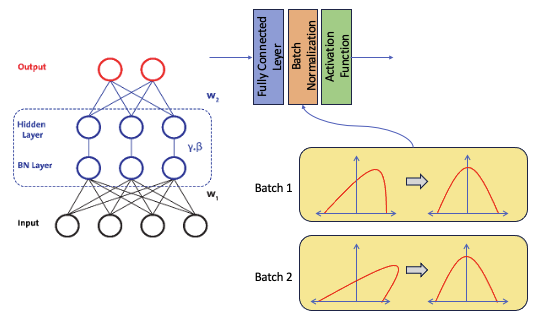
- 한 번에 들어오는 배치 단위로 정규화
- 각 층에서 활성화 함수를 통과하기 전에 수행
입력에 대해 평균을 0으로 만들고, 정규화
그리고 정규화된 데이터에 대해 스케일과 Shift를 수행하기 위해 매개변수 감마와 베타를 사용
$\gamma$는 스케일을 위해 사용, $\beta$는 Shift를 위해 사용

추론 단계에서는 평균과 분산을 계산하지 못함
따라서, 학습 단계에 저장한 배치 단위의 평균과 분산 값을 이용해 정규화

4. 층 정규화

batch Normalization이 가지고 있던 Batch에 대한 의존도를 제거하고
batch가 아닌 layer를 기반으로하여 Normalization을 수행
References
[Deep Learning] Batch Normalization (배치 정규화)
Batch Normalization은 2015년에 아래의 논문에서 나온 개념이다.Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate ShiftData Normaliz
velog.io
06-08 기울기 소실(Gradient Vanishing)과 폭주(Exploding)
깊은 인공 신경망을 학습하다보면 역전파 과정에서 입력층으로 갈 수록 기울기(Gradient)가 점차적으로 작아지는 현상이 발생할 수 있습니다. 입력층에 가까운 층들에서 가중치들이…
wikidocs.net