decision tree(의사결정나무)
순차적으로 질문을 던져서 답을 고르게 하는 방식으로 의사결정을 하는 머신러닝 모델

한번의 분기 때마다 변수 영역을 두 개로 구분
결정 트리에서 질문이나 정답을 담은 네모 상자를 노드(Node)라고 함
맨 처음 분류 기준 (즉, 첫 질문)을 Root Node라고 함
맨 마지막 노드는 Terminal Node 혹은 Leaf Node
특징
- 분류, 회귀 모두 가능한 지도학습 모델
- 결정 트리의 Leaf Node가 가장 섞이지 않은 상태로 완전히 분류되는 것, 즉 복잡성(Entropy)이 낮도록 만들어야 함
- 주로 f1-score를 통해 평가
그렇다면, 위에서 가지를 어떤 기준으로 뻗어나갈지 그 기준을 어떻게 정하는 것일까?
1. 데이터를 가장 잘 구분할 수 있는 질문을 기준으로 나눔

2. 나뉜 범주에서 또 데이터를 잘 구분할 수 있는 질문을 기준으로 나눔

3. 계속 나눔
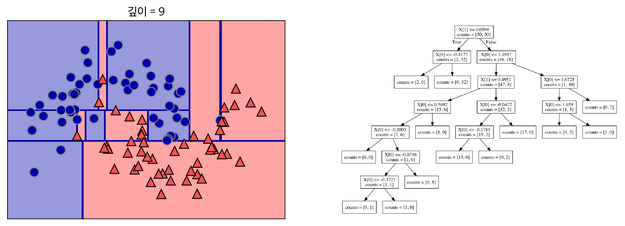
일반적으로 트리 만들기를 모든 리프 노드가 순수 노드가 될 때까지 진행하면 모델이 매우 복잡해지고 훈련 데이터에 과대적합이 발생
이를 해결하기 위해 가지치기(Pruning)라는 기법을 사용
가지치기
즉, 최대 깊이나 터미널 노드의 최대 개수, 혹은 한 노드가 분할하기 위한 최소 데이터 수를 제한하는 것
min_sample_split 파라미터를 조정하여 한 노드에 들어있는 최소 데이터 수를 정해줄 수 있음
파라미터를 10으로 두면 한 노드에 10개의 데이터가 있을 때 더 이상 분기를 하지 않음
max_depth를 통해서 최대 깊이를 지정할 수 있음
하지만, 가장 적은 노드로 높은 예측을 가지도록 균일하게 나누는 게 어쨌든 효율적 !!

A가 가장 균일도가 낮고,
C가 가장 균일도가 높다.
이러한 데이터셋의 균일도는 데이터를 구분하는 데 있어서 필요한 정보의 양에 영향을 미침
이러한 정보의 균일도를 측정하는 방법으로는
- 엔트로피를 이용한 정보이득( Information Gain)지수
- 지니계수
1. 정보이득(Information Gain)
엔트로피라는 개념을 기반으로 둠
- 정보이득지수 = 1 - (엔트로피 지수)
Entropy
- 주어진 데이터 집합의 혼잡도
- 서로 다른 값들이 섞여 있으면 엔트로피가 높고, 같은 값으로 섞여있으면 엔트로피가 낮음
결정트리는 정보 이득 지수로 분할을 함
2. 지니계수
- 낮을 수록 데이터의 균일도가 높고, 지니계수가 높으면 균일도가 낮음

불순도는 이것은 여러 범주가 섞여 있는 정도를 의미
예를들어 (45%,55%)인 샘플은 불순도가 높은 것이며
(80%,20%)인 샘플이 있다면 상대적으로 위의 상태보다 불순도가 낮다고 볼 수 있음
불순도가 낮다 = 지니계수가 낮다 = 엔트로피가 낮다 = 균일도가 높다
장점
- 정보의 균일도라는 룰을 기반으로 하고 있어서 알고리즘이 쉽고 직관적
- 회귀와 분류 모두 가능
- 특성들간의 상관관계가 많아도 트리모델은 영향을 받지 않음
단점
- 새로운 sample이 들어오면 속수무책
References
머신러닝 - 4. 결정 트리(Decision Tree)
결정 트리(Decision Tree, 의사결정트리, 의사결정나무라고도 함)는 분류(Classification)와 회귀(Regression) 모두 가능한 지도 학습 모델 중 하나입니다. 결정 트리는 스무고개 하듯이 예/아니오 질문을 이
bkshin.tistory.com
https://wooono.tistory.com/104
[ML] 의사결정트리(Decision Tree) 란?
의사결정트리(Decision Tree)란? 의사결정트리는 일련의 분류 규칙을 통해 데이터를 분류, 회귀하는 지도 학습 모델 중 하나이며, 결과 모델이 Tree 구조를 가지고 있기 때문에 Decision Tree라는 이름을
wooono.tistory.com
https://velog.io/@ljs7463/%EA%B2%B0%EC%A0%95%ED%8A%B8%EB%A6%ACDecision-Tree%EB%AA%A8%EB%8D%B8Model
결정트리(Decision Tree)모델(Model)
결정트리 모델이란 데이터에 있는 규칙을 학습을 통해 자동으로 찾아내 트리 (Tree)기반의 분류 규칙을 만드는것으로 이 모양이 나무를 닮아 Tree모델이다.구조 구조 설명루트노드(root) : 트리가
velog.io
'전공 > 머신러닝' 카테고리의 다른 글
| [ML] 나이브 베이즈 (Naive Bayes) (0) | 2024.11.20 |
|---|---|
| [ML] 머신러닝 평가지표, Confusion Matrix/Accuracy/MSE.. (0) | 2024.11.20 |
| [ML] 소프트맥스 회귀 (Softmax Regression) (0) | 2024.11.20 |
| [ML] 원핫인코딩(One-Hot Encoding) (0) | 2024.11.20 |
| [ML] 로지스틱 회귀 (Logistic Regression) (0) | 2024.11.09 |



