하이퍼커넥트 AI Lab에서 발표한 논문으로, Interspeech 2020에 실려있음
이 논문에선 제한된 데이터만을 가지고 학습 가능한 TTS 시스템을 연구함
TTS 연구에서 가장 활발하게 사용되고 있는 Tacotron2 모델을 베이스로 연구하였다고 함
Attentron 모델은 attention을 활용하여 따라하고자 하는 화자의 특징에 대한 정보를 스펙트로그램으로부터 직접 가져와 사용
Abstract
적은 양의 데이터만으로도 화자를 복제할 수 있는 few-shot TTS 시스템을 개발
Attentron이라는 few-shot TTS 모델을 제안
Attentron은 두 개의 특수한 인코더를 가지고 있는데,
- fine-grained Encoder
Attention을 사용하여 가변 길이의 스타일 정보 추출 - coarse-grained Encoder
훈련에 포함되지 않은 화자의 음성을 합성할 때, 이해할 수 없는 소음(gibberish)가 발생하는 문제를 방지
- 훈련 과정에서 학습하지 않은 화자의 목소리도 복제 가능
- 인퍼런스 오디오 개수를 자유롭게 확장 가능
실험 결과는 화자유사도와 음질 측면에서 SOTA 모델들보다 뛰어난 성능을 보임
1. Introduction
기존의 muiti-speaker TTS은 훈련된 화자만을 모델링하기 위해 대량의 음성 데이터가 필요
그러나, 현실적으로 personailized 응용 사례에서는 이러한 방대한 데이터를 확보하기 어려움
소량의 음성 샘플만으로 화자를 복제할 수 있는 few-shot TTS 시스템이 필요하다고 느낌
기존 연구에서는 few-shot TTS 구현을 위해 speaker adaptation 방식을 제안해 옴
Speaker adaptation
이 방식은 다수의 화자가 포함된 대규모 데이터셋으로 모델을 사전 학습한 후,
소량의 대상 화자 데이터로 추가 학습하는 과정이 필요했음.
하지만 이러한 방법은 최소 몇 분 이상의 음성 샘플과 추가적인 미세 조정(fine-tuning) 과정이 필요하기 때문에,
즉각적인 화자 복제가 요구되는 in-the-wild 환경에서는 적용이 어려움
이전 연구들 중 일부는 TTS 모델과 함께 공동 학습된 speaker encoder 또는 speaker verification 모델을 활용하여,
추가적인 fine-tuning없이 화자 임베딩을 예측하는 방식으로, 훈련되지 않은 화자의 목소리를 복제하려고 했었음
$\to$ 단일 임베딩으로 speaker의 identity과 발화 스타일을 모두 효과적으로 표현하는 것은 어려움
그래서 이전 연구에서는 발화 스타일, 운율, 잡음 등 특정 속성을 담당하는 여러 개의 특수화된 임베딩(specialized embeddings)을 제안하거나, 시간 정보를 유지할 수 있는 가변 길이(variable-length) 임베딩 방식이 연구되었지만, 여러 한계가 존재했음.
또한, 실제 응용 환경에서는 다수의 참조 음성을 사용할 수 있음에도 불구하고, 다중 참조 샘플을 활용하여 음성 품질을 향상시키는 연구가 부족한 상황.
훈련되지 않은 화자를 위한 few-shot TTS의 새로운 아키텍처인 Attentron을 제안
- fine-grained Encoder
어텐션 메커니즘을 포함하여 여러 개의 참조 샘플에서 화자의 발화 특징을 따라하기 위한 상세한 스타일 정보를 추출 - coarse-grained Encoder
모방하려고 하는 화자 음성의 전체적인 정보를 추출하여 출력을 안정화하는 역할
위 두개의 인코더를 활용하여,
multi-speaker TTS가 소수의 참조 샘플만으로도 훈련되지 않은 화자를 복제할 수 있도록 하며,
여러 개의 참조 샘플에서 유의미한 위치만 찾는 어텐션 메커니즘을 제안
2. Attentron Architecture
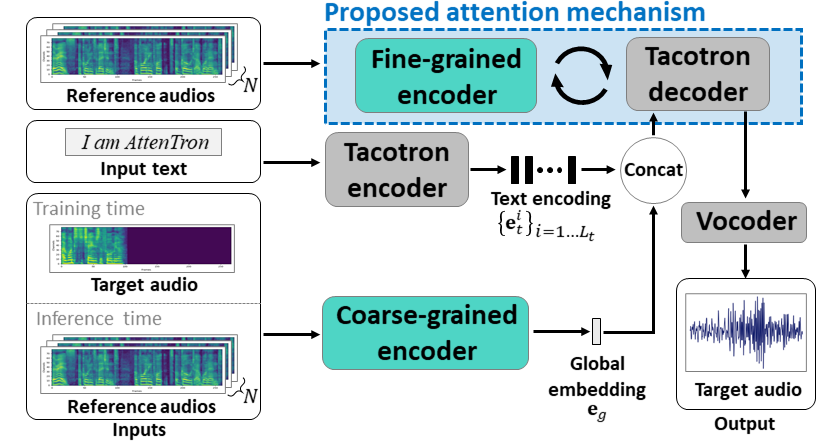
Tacotron 2를 기반으로 한 모델이며,
텍스트 시퀀스를 입력으로 받아 멜 스펙트로그램 프레임 시퀀스를 출력으로 생성함
기존 모델과 다른 것은 두 개의 추가적인 인코더(Fine-grained, Coarse-grained)가 있다는 것
참고
- 실험에서는 waveRNN 보코더를 사용
음성 합성 과정
- Coarse -grained 인코더는 global embedding $e_g$을 만들고,
이 벡터는 입력 오디오 파일들의 시간적 정보를 하나의 벡터로 aggeression. - Tacotron 인코더가 생성한 Text encoding ${\{e^i_t}\}_{i=1...L_t}$와 $e_g$를 결합하여 Tacotron 디코더의 입력으로 들어감
- Fine-grained 인코더는 그림의 Proposed attention mechanism을 활용하여
시간 정보를 유지하는 가변 길이의 임베딩을 추출 - 3번의 임베딩을 Tacotron 디코더에 입력하여 스펙트로그램 프레임을 자동회귀 방식으로 합성
- 마지막으로, 보코더가 생성된 스펙트로그램을 음성으로 변환
📌 내가 이해한 합성 과정


📌 왜 시간 정보를 유지하는 가변 길이의 임베딩이 필요하지??
기존 TTS 시스템에서 화자의 스타일(운율, 억양, 강세 등)을 임베딩할 때 단일 벡터(single embedding)만 사용하면 문제가 생길 수 있음
1️⃣ 문제 1 : 참조 음성이 2초짜리라면, 단일 벡터는 이 2초 동안의 모든 스타일을 하나로 요약해야 함
그런데 이 단일 벡터를 가지고 10초짜리 문장을 합성하려고 하면?
즉, 긴 문장을 만들 때 화자의 스타일이 일관되지 않거나 왜곡될 수 있음.
2️⃣ 문제 2 : 시간에 따라 변화하는 스타일을 표현하기 어려움
사람이 말할 때, 단어마다 강세나 억양이 다르게 변함.
하지만 단일 벡터로 모든 스타일을 표현하면 시간에 따른 변화를 반영하기 어려움.
✅ 이 문제점을 시간 정보를 유지하는 가변 길이 임베딩이 해결
- 운율, 억양, 강세 같은 스타일을 시점별로 보존할 수 있음
- 음성이 길든 짧든 각 프레임을 유지하여 짧은 참조 샘플로도 안정적인 합성이 가능
- 시간별로 다르게 말하는 스타일을 반영 가능
2-1. Fine-grained Encoder and Attention Mechanism
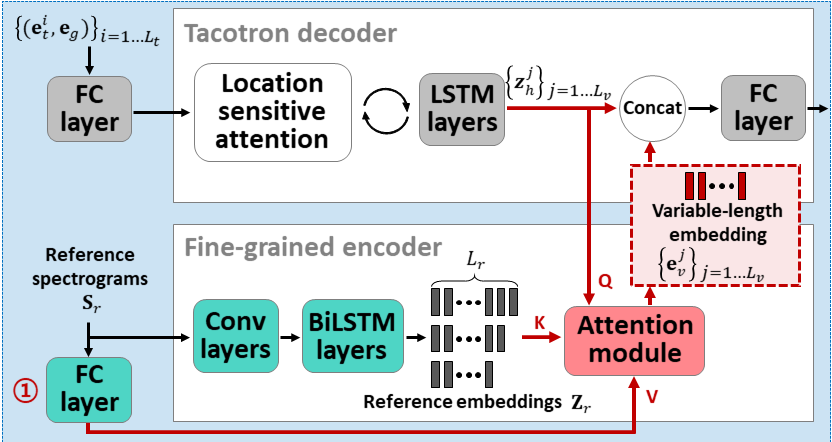
위에서도 설명했듯이 Fine-grained 인코더는 참조 샘플에서 세밀한 스타일 정보를 추출하기 위해 필요하다고 언급함
이 인코더는 다음과 같은 목표가 있음
- 다수의 참조 오디오 파일을 효과적으로 활용해야 함
- 가변 길이의 임베딩을 사용하여 세부 정보를 유지해야 함
- 참조 오디오 원본 특성에 가까운 특징을 활용하여 일반화를 향상해야 함
Attentron은 Scaled dot-product attention을 사용하여 참조 오디오 스펙트로그램에서 가장 관련성이 높은 프레임에 집중할 수 있도록 함
Fine-grained 인코더의 입력은 Target audio와 동일한 화자가 말한 N개의 참조 오디오 파일임
그것을 mel-spectrogram으로 변환하고, 최대 스펙트로그램 길이 $L_r$에 맞추기 위해 패딩을 추가
변환된 참조 스펙트로그램 $S_r \in \mathbb{R}^{N \times L_r \times n_{mels}} $은
- 두 개의 convolution 레이어를 지나고
- 두 개의 양방향 LSTM 레이어를 통과하여
- Reference embeddings $Z_r \in \mathbb{R}^{N \times L_r \times d_r}$을 생성
여기서 $n_{mels}$은 멜 스펙트로그램의 멜 빈 개수
j번째(프레임) 디코딩 단계에서 디코더 LSTM의 은닉 상태 $Z^j_h$가 주어지면,
어텐션 쿼리,키, 값 $Q_j, K, V$, 그리고 가변 길이 임베딩의 j번째 성분 $e^j_v \in \mathbb{R}^{d_v}$는 다음과 같이 계산
$$ Q_j = z^j_hW_q \in \mathbb{R}^{d_m}$$
$$K = Z_rW_k \in \mathbb{R}^{N \times L_r \times d_m}$$
$$V = S_rW_v \in \mathbb{R}^{N \times L_r \times d_v} $$
$$e^j_v = A(Q^j, K, V) = softmax(\frac{f(Q^j)f(K)^T}{\sqrt{d_m}})f(V)$$
여기서 $f$는 flatten 함수이며, $W$는 linear projection matrices임
K와 V는 flatten 함수를 통해 3차원에서 N과 $L_r$이 합쳐저 2차원이 됨 $\to( NL_r, d)$
📌 왜 $Z^j_h$ (디코더 LSTM의 은닉 상태)와 쿼리 Q가 매칭되는가?
디코더의 상태 $Z^j_h$ 와 Key( $Z_r $)를 비교하여, 디코더가 현재 필요로 하는 스타일 정보 V를 찾아냄!
👉 디코더가 생성해야 할 현재 프레임과 가장 관련된 스타일 정보를 찾기 위해서
그 결과로 Value 에서 적절한 정보를 가져와 가변 길이 임베딩을 생성.
가변 길이 임베딩의 각 성분 $e_v^j$은 $z^j_h$와 연결(concatenation) 되어 완전연결(fully-connected) 레이어에 입력
이 과정은 자동회귀 방식으로 반복되며 스펙트로그램이 생성될 때까지 진행됨
만들어진 가변 길이 임베딩 e는 다음 입력으로 넘어가 최종 스펙트로그램을 생성하게 됨
참고로, 참조 스펙트로그램은 과적합(overfitting)될 가능성이 높아지기 때문에 어텐션 값을 생성하기 위해 오직 하나의 fully-connected 레이어만 통과
📌 자동회귀 방식으로 반복?
한 번에 전체 스펙트로그램을 생성하는 것이 아니라, 프레임을 하나씩 순차적으로 생성
✅ 이전 프레임을 보고 다음 프레임을 예측하는 과정이 반복되면서 최종적인 스펙트로그램이 완성
2-2. Coarse-grained Encoder
같은 화자의 음성이라도 특징이 달라질 수 있으며, 같은 스크립트를 읽어도 차이가 존재할 수 있음
따라서, 입력된 텍스트만으로 음성을 합성하는 것은 본질적으로 비결정적(non-deterministic)인 일대다(one-to-many) 문제이며, 이는 합성된 음성이 불안정해지는 원인
이 문제를 안정화하기 위해, coarse-grained 인코더는 음성의 전반적인 정보를 포함하는 전역 임베딩(global embedding)을 생성하도록 설계됨
출력 음성의 범위를 좁히고, 문제를 one-to-one에 가깝게 만듦으로써 안정성을 향상시킴
추가적인 손실 함수없이 전역 임베딩 $e_g \in \mathbb{R}^{d_g}$을 생성하는 단순한 네트워크를 사용
coarse-grained 인코더는
- 두 개의 컨볼루션 레이어
- 두 개의 양방향 레이어
로 구성되어 있음
마지막에는 average pooling 레이어가 있어 global vector를 생성
또한, Training에 target audio file을 입력으로 사용하지만, Inference 시에는 목표 화자가 말한 참조 샘플을 입력으로 사용
마지막 레이어는 다수의 참조 샘플에서 추출된 임베딩을 평균 내어 단일 전역 임베딩(single global embedding)을 생성
제가 이해한 것이 맞겠죠..???

4. Experimental Result
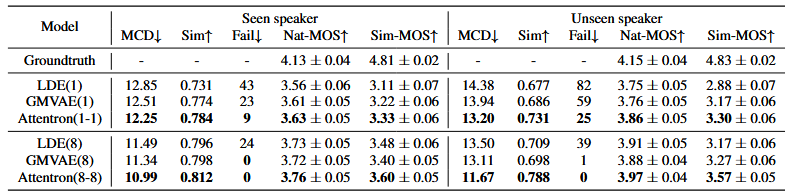
훈련된 화자(seen speakers)에 대해서는 눈에 띄는 차이(remarkable difference)가 없지만,
훈련되지 않은 화자(unseen speakers)를 대상으로 한 음성 합성에서는 제안된 모델이 기존 베이스라인 모델보다 현저하게 우수한 성능을 보인다.
References
https://hyperconnect.github.io/2020/11/30/ailab-siren.html
Few-shot text-to-speech 를 향한 여정 - Attentron
AI Lab 에서 진행한 음성 합성 프로젝트와 그 결과에 대해서 소개합니다.
hyperconnect.github.io
'논문' 카테고리의 다른 글
| [리뷰] Mamba: Linear-Time Sequence Modeling with Selective State Spaces (1) | 2025.03.16 |
|---|---|
| [리뷰] Tacotron2 알아보기 + 논문 리뷰 (0) | 2025.03.13 |

