NATURAL TTS SYNTHESIS BY CONDITIONING WAVENET ON MEL SPECTROGRAM PREDICTIONS
Tacotron2는 2018년 구글에서 발표한 새로운 TTS 모델

기존의 TTS 시스템은 복잡한 전처리 및 음성 합성 과정이 필요했지만,
Tacotron 2는 이를 딥러닝 기반으로 통합해 자연스러운 음성을 생성
➡️ Tacotron 2의 주요 특징:
- 문자(character) 입력 → 음성 출력까지 엔드투엔드(End-to-End) 학습 가능
- Mel Spectrogram을 중간 단계로 사용
- WaveNet 기반 Vocoder 사용 → 고품질 음성 생성 가능
Abstract
Tacotron2는 character embedding을 mel-spectrogram으로 매핑하는 recurrent sequence-to-sequence feature prediction network와 그 스펙트로그램에서 time-domain waveform을 합성하는 보코더 역할을 하는 수정된 WaveNet 모델로 구성
1. Introduction
보코더를 통해 음성 합성 분야에서 다양한 문제를 해결할 수 있었지만,
실제 인간 음성과 비교했을 때 여전히 탁하고 부자연스러움
- WaveNet은 time-domain waveform의 생성 모델로, 실제 인간 음성의 품질에 근접하는 오디오 품절을 생성
그러나, WaveNet의 입력(언어적 특징, 예측된 로그 기본 주파수(log fundamental frequency), 음소 지속 시간)은 이를 생성하기 위해 상당한 도메인 전문 지식이 필요
- Tacotron은 문자 시퀀스로부터 스펙트로그램의 크기를 생성하기 위한 sequence-to-sequence 아키텍처
기존 음성 합성 파이프라인에서 언어적 및 음향적 특징을 생성하는 과정을 단일 신경망이 학습을 통해 자동으로 처리하도록 단순화
또한, 보코딩을 위해 Griffin-Lim 알고리즘을 사용했었는데, WaveNet 같은 접근 방식보다 낮은 오디오 품질을 생성하기에 이 논문에서 그에 대한 해결책을 제시
✅ 이 방법은 멜 스펙트로그램을 생성하는 Tacotron 스타일의 시퀀스-투-시퀀스 모델과 수정된 WaveNet 보코더를 사용
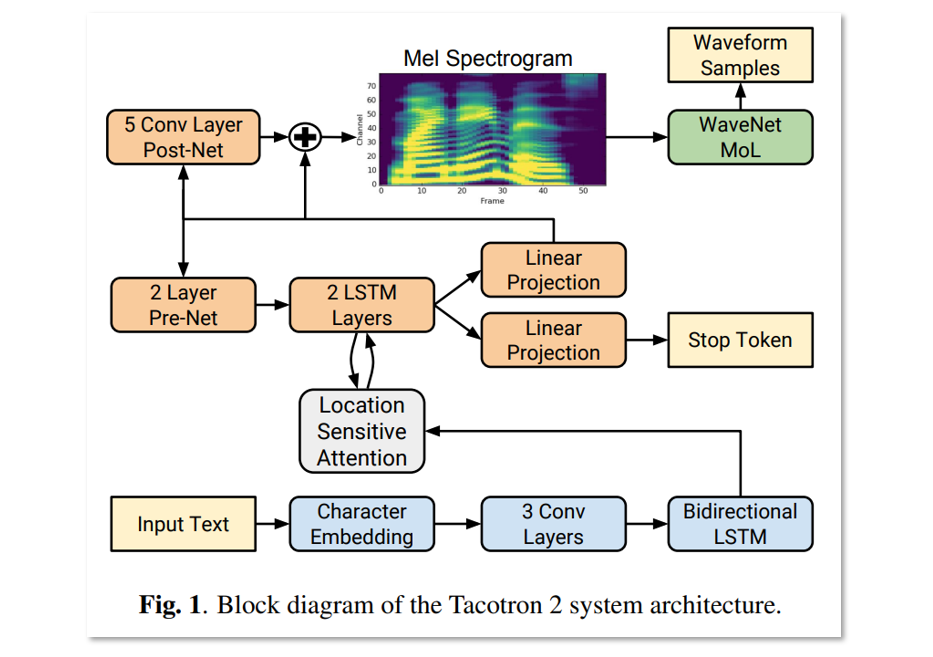
2. Model Architecture
- 입력된 문자 시퀀스로부터 멜 스펙트로그램 프레임 시퀀스를 예측하는 어텐션을 포함한 recurrent sequence-to-sequence 특징 예측 네트워크
- 예측된 멜 스펙트로그램 프레임을 조건으로 하여 time-domain 파형 샘플을 생성하는 수정된 WaveNet
2.1. Intermediate Feature Representation
이 연구에서는 Acoustic model과 Vocoder model을 잇는 사이의 low-level acoustic representation으로 mel-frequency spectrogram을 선택
tiem-domain 파형에서 쉽게 계산할 수 있는 표현 방식을 사용하면 두 구성 요소를 별도로 훈련 가능
또한, 멜 스펙트로그램은 파형 샘플보다 더 부드럽게 때문에 squared error loss를 사용해 학습하기 용이
👉 이는 각 프레임 내에서 위상(phase)에 대해 불변(invariant)하기 때문
멜 스펙트로그램은 STFT의 주파수 축에 non-linear transform을 적용하여 얻어지므로 인간의 청각 반응을 잘 반영
멜 scale의 자세한 설명은 여기
그러나 멜 스펙트로그램은 선형 스펙트로그램보다 더 많은 정보를 버리기 때문에(고주파 단순화) 복원이 더 어려워짐
그럼에도 불구하고 WaveNet의 복잡한 입력들보다 더 단순하기 떄문에
멜 스펙트로그램을 조건으로 하는 WaveNet 모델이 이를 기반으로 오디오를 생성하는 것은 상대적으로 용이
📌 WaveNet에서 사용된 입력 특징과 멜 스펙트로그램의 차이
WaveNet에서 처음에 사용했던 입력은 다음과 같음:
- 언어적 특징(Linguistic Features) → 문장에서 추출된 문법 구조, 형태소 등
- 기본 주파수(F0) → 음성의 높낮이 (pitch) 정보
- 음소 지속 시간(Phoneme Duration) → 각 음소가 발음되는 시간
➡️ 이런 특징은 사전 언어 분석 과정이 필요하기 때문에 복잡하고 도메인 지식이 필요
➡️ 따라서 WaveNet에서 이 입력을 생성하는 데 복잡한 전처리 과정이 필요
👉 결국 복잡한 언어적 특징 대신 멜 스펙트로그램을 사용하면 WaveNet이 더 쉽게 학습하고 좋은 성능을 낼 수 있다는 의미
2.2. Spectrogram Prediction Network
Mel-spectrogram
- 프레임 크기(frame size) : 50ms
- 프레임 홉(frame hop) : 12.5ms
- 윈도우 함수(window function) : Hann 윈도우
STFT의 크기 성분(magnitude)을 125Hz에서 7.6kHz에 걸친 80채널 멜 필터뱅크를 사용해 멜 스케일로 변환한 다음, 로그 동적 범위 압축을 적용
로그 압축 전에, 필터뱅크 출력의 크기는 0.01로 최소값을 잘라내어 로그 도메인에서의 동적 범위를 제한
✅ Tacotron2의 모델은 attention 메커니즘을 적용한 encoder와 decoder로 구성
Encoder
- 문자 시퀀스를 hidden feature representation으로 변환
입력 문자는 학습된 512차원의 임베딩으로 변환됨
그 임베딩은 3개의 합성곱 층을 통과하게 됨
- 각 층은 512개의 필터 사용
- 필터 크기 : 5 x 1
- 배치 정규화 적용 후, ReLU 사용
➡️ 이러한 합성곱 층은 입력 문자 시퀀스의 long-term context을 모델링
한 문자만 보고 다음 문자를 예측하는 것이 아니라, 연속된 문자 시퀀스를 보고 예측한다는 의미
마지막 합성곱 층의 출력은 512개의 유닛(각 방향에 256개)을 포함하는 단일 양방향(bi-directional) LSTM 층으로 전달되어 인코딩된 특징을 생성

인코더의 출력은 어텐션 네트워크의 입력으로 사용
Attention Mechanism
이 네트워크는 전체 인코딩된 시퀀스를 요약하고,
디코더의 각 출력 단계에서 고정 길이의 컨텍스트 벡터로 변환
Attention-based models for speech recognition(2015)에서 제안된 location-sensitive-attention을 사용
✅ location-sensitive-attention의 특징:
- 기본 additive attention 메커니즘을 확장한 구조
- 이전 디코더 시간 단계에서의 cumulative attention weights를 추가 입력으로 사용
- 모델이 입력을 일관되게 순차적으로 처리하도록 유도 → 특정 하위 시퀀스가 반복되거나 무시되는 오류 방지
➡️ 어텐션 확률은 입력과 로케이션 특성을 128차원 hidden representation으로 projection한 후 계산
➡️ 로케이션 특성은 길이 31의 1D 합성곱 필터 32개를 사용해 계산
Decoder
- 인코더의 변환된 표현을 기반으로 스펙트로그램을 예측
자기회귀 RNN으로, 인코딩된 입력으로부터 멜 스펙트로그램을 한 프레임씩 예측
- 이전 시점의 예측값은 2개의 fully-connected layer를 통과
이 완전 연결층에는 각 256개의 ReLU 유닛이 포함됨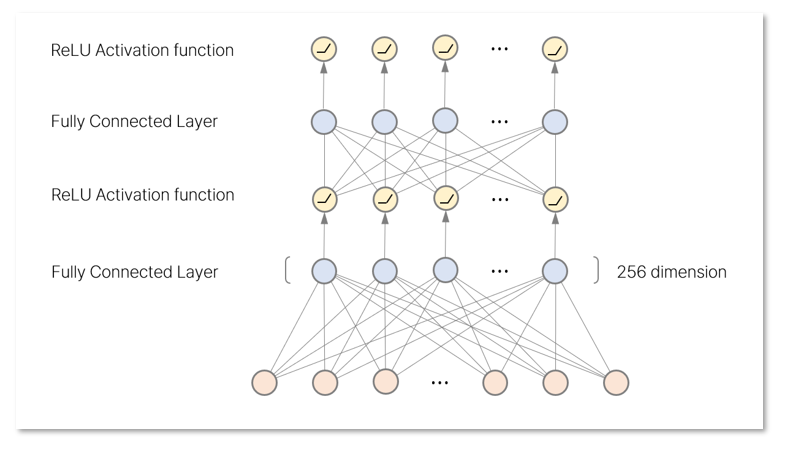
📌 2개의 완전 연결층의 초기 입력 값은 무엇일까?더보기- Tacotron 2에서 처음 시점($t_0$)에는 이전 시점의 예측값이 없기 때문에 다음과 같은 값이 입력
✅ 초기 입력값 (t₀) → Zero Frame 사용
모든 값이 0인 멜 스펙트로그램 프레임을 입력으로 사용
- Tacotron 2에서 처음 시점($t_0$)에는 이전 시점의 예측값이 없기 때문에 다음과 같은 값이 입력
- prenet 출력과 attention context vector이 연결된 후 2개의 LSTM 레이어를 거침
2개의 단일 방향(unidirectional) LSTM 층 → 각 층에 1024개 유닛 포함 - LSTM 출력과 attention context vector는 다시 연결
- 선형 변환층 (linear transform layer)을 통해 다음 스펙트로그램 프레임 예측
- 예측된 스펙트로그램은 Post-Net을 통과하여 보정됨
Post-Net은 5개의 CNN층으로 구성
잔여 성분(residual)을 예측하여 보정함으로써 전체 재구성 성능을 개선
📌 잔여 성분이 뭔데?
더보기쉽게 말해 예측값에서 빠진 부분이나 부족한 디테일을 의미
처음에 디코더에서 생성된 스펙트로그램은 완벽하지 않음
( LSTM은 출력값이 이전 상태에서 자연스럽게 이어지도록 하려는 성향이 있다고 함 )
Post-Net는 따라서 그 부족한 부분을 보완해주는 역할을 함
Post-Net에서 5개의 CNN 층을 통해 다음과 같은 처리가 수행됨
→ 고주파 성분 및 디테일 복원
→ 미세한 소리의 명확성 개선
✅ 어떻게 가능하냐?
고주파 성분은 짧은 시간 내에 발생하는 세밀한 변화
CNN 필터 크기가 작으면 → 작은 변화까지 포착 가능
특히 고주파 성분은 필터에서 잘 감지됨
➡️ CNN은 고주파 성분을 감지하고 학습할 수 있음
✅ CNN 층의 출력값은 디코더에서 생성된 원래 출력값에 더해짐
최종 출력 = 디코더 출력값 + Post-Net 출력값 (잔여 성분)
➡️ 따라서 LSTM(디코더) + CNN 조합으로 시간적 패턴과 공간적 디테일을 동시에 학습
➡️ 이때 Post-Net 출력값이 바로 잔여 성분(Residual)입니다.
- 예측된 스펙트로그램은 이전 step의 결과와 이어 붙임
→ 다음 스펙트로그램 프레임 예측을 위해 현재 결과는 Pre-Net으로 전달
또한, 현재 음성합성이 끝났는지를 판단하기 위해 또 다른 선형 변환 레이어와 시그모이드 함수를 사용
✅ 출력 종료는 해당 확률이 0.5를 초과할 때 발생

2.3. WaveNet Vocoder
- Tacotron 2는 수정된 WaveNet 아키텍처를 사용해 멜 스펙트로그램 → 시간 도메인 파형(time-domain waveform) 변환
30개의 dilated convolution layer를 사용 → 3개 팽창 주기로 그룹화 됨
- 각 레이어의 팽창률(dilation rate):
$$2^k mod 10$$
➡️ 간격이 $2^k$로 점점 커지면서 더 넓은 범위에서 정보를 학습합니다.
스펙트로그램의 12.5ms 프레임 홉과 호환되도록 기존 3개 업샘플링 → 2개 업샘플링으로 축소
소프트맥스 대신 10개 성분의 로지스틱 분포 혼합(MoL) 사용 → 24kHz에서 16비트 샘플 생성
WaveNet 스택 출력 → ReLU → 선형 투영 → MoL의 평균, 로그 스케일, 혼합 가중치 예측
손실 함수 → 음의 로그 우도로 계산됨
References
https://killerwhale0917.tistory.com/35
Tacotron2: Natural TTS Synthesis by Conditioning WaveNet on Mel Spectrogram Predictions
https://arxiv.org/abs/1712.05884 Natural TTS Synthesis by Conditioning WaveNet on Mel Spectrogram Predictions This paper describes Tacotron 2, a neural network architecture for speech synthesis directly from text. The system is composed of a recurrent sequ
killerwhale0917.tistory.com
'논문' 카테고리의 다른 글
| [리뷰] Mamba: Linear-Time Sequence Modeling with Selective State Spaces (1) | 2025.03.16 |
|---|---|
| [리뷰] Attentron: Few-Shot Text-to-Speech Utilizing Attention-Based Variable-Length Embedding (0) | 2025.02.20 |

