1. LeNet (1998)

- Yann LeCun이 제안한 최초의 CNN 모델
- 손글씨 숫자 인식(MNIST) 문제 해결을 위해 개발
- 합성곱(Convolution) + 풀링(Pooling) 구조 최초 도입

구조:
- 입력 → 합성곱 → 풀링 → 합성곱 → 풀링 → 완전연결층(FC) → 출력
- Filter size : 5x5
- stride : 1
- Pooling : 2x2 average pooling
- Activation function:
- 대부분의 unit이 sigmoid를 사용.
- F6에서는 tanh를 사용.
- 최종적인 output layer인 F7에서는 RBF (Euclidian Radia basis function unit)을 사용
- loss function : MSE
성능:
✅ MNIST 데이터셋에서 약 99% 정확도 달성
2. AlexNet (2012)

- 딥러닝의 새로운 시대를 연 모델
- ImageNet 대회(ILSVRC)에서 압도적 성능으로 우승
- LeNet보다 훨씬 깊은 네트워크 구조 + ReLU 활성화 함수 도입
구조:
기본적인 구조는 LeNet과 비슷하나, GPU 2대를 이용하여 빠른 연산이 가능해지면서 병렬적인 구조가 가능해짐
- 입력 → 합성곱 → 풀링 → 합성곱 → 풀링 → FC → 출력
- 활성화 함수: ReLU → 학습 속도 증가
- Over-fitting 방지를 위해 도입한 방법
- Data augmentation : 데이터셋 이미지를 좌우 반전을 시키거나 (flip augmentation), 이미지를 잘라서 (Crop augmentation) 데이터 수를 늘림. 또 RGB 값을 조정하여 (jittering) 데이터 수를 늘림.
- Dropout: rate 0.5
- Norm layer 사용 : 원시적인 형태의 batch normalization , 지금은 쓰이지 않음
- Batch size : 128
- SGD momentum : 0.9
- learning rate : 1e-2 , validation accuracy에 따라 manual 하게 낮춤
- L2 weigh decay : 5e-4
- 7 CNN ensemble : error 18.2 % --> 15.4%
성능:
✅ ILSVRC 2012 우승
✅ 이미지 분류 오류율 약 16%
CNN 모델의 고질적인 문제는 Black box,
즉 특정 layer는 이미지의 어떤 부분을 검출하는지, 모델이 왜 잘 작동하는지 알 수 없다는 점
ZFNet은 feature map을 시각화하여 블랙박스를 들여다보고, 모델의 성능을 개선하는 것을 목표로 고안됨
3. ZFNet (2013)

- AlexNet 개선 모델
- 합성곱 필터 크기와 stride 크기 최적화

n-1번째 pooled maps이 "Convolution > ReLU activation > Max Pooling"을 통과하여
n번째 Pooled Maps을 생성하였다고 가정.
저자들은 n번째 Pooled Maps에 해당 구조의 역과정을 수행하여 n-1번째 pooled maps을 복원해보고자 한 것임
📌 AlexNet의 각 layer를 시각화한 결과
Layer 1이나 2를 시각화한 결과 이미지의 모서리, 경계, 색과 같은 Low level feature를 잡아내는 것을 볼 수 있습니다. Layer 3에서는 전반적인 패턴, 사물과 객체의 경계를 잡아내고 있습니다.
Layer 5에서는 사물이나 개체의 전부를 보여주며 각각 다른 위치나 자세를 취하고 있는 모습을 잡아내고 있습니다.
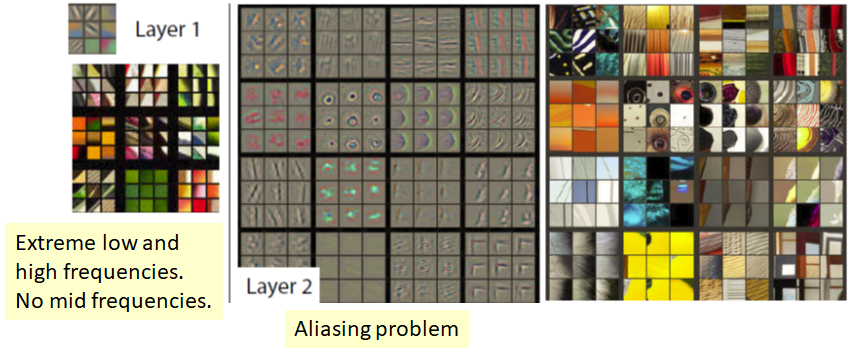


구조:
- AlexNet과 유사한 구조지만 필터 크기 및 stride 최적화
- 시각화 도구로 내부 합성곱 필터 학습 과정 분석
성능:
✅ ILSVRC 2013 우승 (Top-5 오류율 11.2%)
앞서 8 layer 이하의 비교적 적은 수의 layer를 가진 CNN 모델을 살펴봄
지금부터 살펴볼 VGG, GoogleNet의 부터는 layer가 더 깊게 쌓이기 시작

그러나 네트워크를 깊게 쌓는다는 것은 생각보다 당시에는 쉬운 일이 아니었음
Gradient vasnishing /exploding 과 같은 문제를 효과적으로 해결할 수 있어야 하고,
파라미터 수가 늘어나 overfitting을 야기할 수 있기 때문!
이제부터 설명할 VGG, GoogLeNet, ResNet은 전술한 문제들을 해결하는 방법이 조금씩 다름
4. VGGNet (2014)

- 매우 깊은 구조의 CNN 모델 (16~19개 레이어)
- 3x3 합성곱 필터 사용 → 세밀한 특징 학습 가능
구조:
- 작은 필터(3x3) + 깊은 구조 (16~19개 레이어)
📌 작은 필터의 효과더보기- 필터의 사이즈를 줄이면서 보다 깊게 쌓았을 때 더 효율적인 receptive field를 가지게 됩니다.
더 넓은 필터를 쓰고 얇은 층을 쌓는 것이나,
작은 필터를 쓰고 깊게 쌓는 것이나 receptive field가 같다는 의미입니다. - Layer가 깊어지면서 다수의 activation function을 통과하므로 더 많은 non-linearity를 줄 수 있게 됩니다.
- 층 당 더 적은 수의 파라미터를 사용하게 됩니다.
ex) 10×10 image에 7×7 filter 적용하여 4×4 feature map 생성 → parameter 개수: 49개
ex) 10×10 image에 3×3 filter 3번 적용하여 4×4 feature map 생성 → parameter 개수: 9개씩 3번 총 27개
- 필터의 사이즈를 줄이면서 보다 깊게 쌓았을 때 더 효율적인 receptive field를 가지게 됩니다.
- ReLU + Max Pooling 사용
성능:
✅ ILSVRC 2014 준우승 (Top-5 오류율 7.3%)
✅ 모델이 너무 커서 메모리 사용량 많음 (GPU 요구)
5. GoogLeNet (2014)

- 구글이 만든 모델
- Inception 모듈 도입 → 필터 크기를 다양하게 설정해 특징 학습 강화
구조:
- 22 layers
- 효과적인 "Inception" module → 필터 크기(1x1, 3x3, 5x5) 병렬 적용
- FC layer 없음 (Output layer 에서만 한번 나옴)
- 오직 500만개의 파라미터 사용
- 글로벌 평균 풀링(Global Average Pooling) 사용
Inception module

기본 CNN 구조에서는 다음과 같은 문제가 존재
- 필터 크기를 어떻게 설정할지 모호함
- 3×3 필터? 5×5 필터? 작은 필터를 여러 번 쓸까?
→ 어떤 필터 크기가 최적인지 알기 어려움
- 3×3 필터? 5×5 필터? 작은 필터를 여러 번 쓸까?
- 계산 비용 증가
- 필터 크기가 커질수록 학습해야 할 파라미터 수가 증가
- 메모리 사용량과 연산 비용이 증가
- 특징 추출의 다양성 부족
- 하나의 필터 크기만 사용하면 데이터의 다양한 패턴을 놓칠 수 있음
👉 그래서 등장한 것이 Inception 모듈
- 다양한 필터 크기(1×1, 3×3, 5×5)를 병렬로 적용
- 필터 크기가 다르면 서로 다른 특징을 학습 가능 → 다양한 크기의 특징 학습 가능
- 1×1 합성곱을 사용해 계산량 감소 및 채널 수 축소
- 최종 출력을 Concatenate(연결) 해서 다음 레이어로 전달

성능:
✅ ILSVRC 2014 우승 (Top-5 오류율 6.7%)
✅ 연산량 감소 + 정확도 향상

CNN을 연구하면서 기존 모델들은 Layer을 깊게 쌓을 수록 성능이 더 좋아질것이라고 예상했지만,
실제로는 20층 이상부터 성능이 낮아지는 현상인 Degradation 문제가 발생
ResNet은 Residual Learning이라는 개념을 통해 모델의 층이 깊어져도 학습이 잘 되도록 구현한 모델
6. ResNet (2015)

- 잔차 연결(Residual Connection) 도입 → 기울기 소실 문제 해결
- 50, 101, 152 레이어 등 다양한 버전 존재
구조:
- 입력 → 합성곱 → 잔차 연결 (Residual Block) → 출력
- 잔차 연결 덕분에 더 깊은 네트워크 학습 가능
$$y = F(x) + x$$
성능:
✅ ILSVRC 2015 우승 (Top-5 오류율 3.6%)
✅ 매우 깊은 모델도 학습 가능

ResNet의 skip-connection을 통해서 identity가 직접 뒤로 전달됨
그런데. 이 identity와 뒷 레이어의 output이 단순 덧셈으로 결합되기 때문에 정보의 흐름을 방해할 여지가 있음
레이어간 정보 흐름을 향상시키기 위해서 단순 덧셈이 아닌 다른 방법을 사용해보자!
7. DenseNet (2017)

- ResNet 개선 버전
- 레이어 출력을 다음 레이어에 직접 연결(concat) → 특징 재활용 강화
구조:
- Dense Block 사용 → 모든 이전 레이어 출력 연결
- 파라미터 수 감소 + 학습 효율 증가
$$x_l = H_l([x_0, x_1, ... , x_{l-1}])$$
성능:
✅ ResNet보다 파라미터 수 적으면서 성능 우수
CNN 모델의 또 다른 단점
채널 간의 상호작용이 부족하다는 것 !!
이 문제를 해결하기 위해서 SENet이 등장
8. SENet (2018)

- 채널의 중요도 강화 → SE 모듈 도입
- 채널 간 상관관계를 학습 → 중요한 채널 강조
구조:
- Squeeze → Excitation → Scaling
- 특징 맵의 채널 중요도를 학습
1. Squeeze (공간 정보 압축)
- 입력에서 공간 정보를 전역 평균 풀링(Global Average Pooling)으로 요약
입력 텐서 크기가 (H × W × C)이면, (1 × 1 × C)로 축소

- $z_c$ → 채널 에 대한 전역 평균 값
- 채널마다 하나의 값이 생성됨 → 전역적 특징 요약
👉 여기서 공간 정보는 사라지고 채널별로 전체 패턴 요약
2. Excitation (채널 간 관계 학습)
- 채널별 중요도를 완전연결층(FC Layer)에서 학습
- $z_c$ 값에 두 개의 FC 레이어 적용 + 비선형 활성화 함수 사용

- $W_1$ = 축소 레이어 → 채널 수 줄임 (차원 축소)
- $W_2$ = 확장 레이어 → 채널 수 복원 (차원 복원)
- = ReLU 활성화 함수
- = Sigmoid 함수
이 과정에서 중요한 점:
- 채널 간의 상호작용 학습
- Sigmoid → 출력값이 [0, 1]로 정규화 → 채널 중요도 결정
3. Scale (채널 재조정)
- 학습된 중요도를 원래 출력에 반영
- 채널별 중요도를 곱하기 연산으로 강화/약화

- $s_c$ = 채널별 중요도
- $x_c$ = 원래 CNN의 출력 값
👉 중요한 채널은 강화되고, 덜 중요한 채널은 억제됨 ✅
성능:
✅ ILSVRC 2018 우승 (Top-5 오류율 3.6%)
기존 CNN 모델 성능을 높이는 방식은 주로 다음 세 가지 방법을 사용:
- 깊이(depth) 증가 → 모델이 깊어지면 더 복잡한 패턴 학습 가능
- 너비(width) 증가 → 채널 수를 늘리면 더 다양한 특징 학습 가능
- 해상도(resolution) 증가 → 고해상도 이미지를 학습하면 더 세밀한 패턴 학습 가능
문제점:
- 깊이만 늘리면 기울기 소실(Vanishing Gradient) 문제 발생
- 너비만 늘리면 연산량 폭발
- 해상도만 늘리면 메모리 부족
- 성능 향상 대비 연산 비용 증가가 비효율적
9. EfficientNet (2019)

- 성능을 높이면서 모델 크기를 최소화
- 복합 스케일링(compound scaling) 도입
👉 단순히 레이어를 깊게 하거나 필터를 늘리는 게 아니라, 너비, 깊이, 해상도를 동시에 최적화한 모델
복합 스케일링 수식
복합 스케일링은 다음과 같은 수식으로 정의:
$$depth = \alpha ^\Phi , width = \beta ^\Phi , resolution = \gamma ^\Phi $$
- $ \Phi $= 전체 모델 크기를 조정하는 스케일링 계수
- α,β,γ = 각각 depth, width, resolution 증가 비율
- 학습을 통해 α, β, γ 값을 최적화
구조:
- MBConv (MobileNet 구조 기반) 사용
- 모델 크기에 비해 성능 우수
- ReLU 대신 Swish 사용 → Swish는 비선형성이 더 풍부
📌 MobileNet이란?
모바일 및 임베디드 기기에서 낮은 연산량으로 높은 성능을 달성하기 위해 설계된 경량화 모델
Depthwise Separable Convolution
Width Multiplier
Resolution Multiplier
등을 사용해 연산량을 줄였다고 하네요~
성능:
✅ 적은 파라미터로 높은 성능 달성
10. ConvNeXt (2022)

- CNN 구조를 트랜스포머처럼 개선
- Layer Normalization
- Depth-wise Separable Convolution 적용
구조:
- ResNet-like 구조 + 트랜스포머에서 배운 기법 적용
- Swish 대신 GELU 활성화 함수 사용
- 성능 향상 + 계산 효율성 증가
성능:
✅ SOTA 성능 달성
References
3) ResNet, ResNet의 확장(레이어 152개 이하)
## ResNet  CNN을 연구하면서 기존 모델들…
wikidocs.net
'전공 > 딥러닝' 카테고리의 다른 글
| [리뷰] AST: Audio Spectrogram Transformer (0) | 2025.04.15 |
|---|---|
| [DL] 오토인코더(Auto-Encoder)와 종류 (2) | 2025.02.06 |
| [DL] 다양한 Convolution 알아보기, Depthwise/Pointwise/Separable/Grouped/Deformable 등등 (4) | 2025.02.06 |
| [DL] 기울기 소실과 폭주 (Gradient Vanishing, Exploding) (1) | 2024.12.13 |
| [DL] 과적합과 규제 (Overfitting, Regularization) (4) | 2024.12.12 |



