21년도 Interspeech에서 accept된 논문으로, 오디오 분류 Task에서 convolution-free를 실현한 모델
논문 링크
AST: Audio Spectrogram Transformer
Abstract
지난 10년 동안, E2E audio classification models의 주요 구성 요소로 CNN이 주로 사용됨
그러나, long-range global context를 잘 포착하지 못하는 문제가 있었음
그 점을 보완하기 위해 CNN에 Self-attention을 추가한 하이브리드 모델이 등장
그러나 CNN에 대한 의존이 정말 필요한 것인지, 순수한 attention 기반 모델도 좋은 성능을 낼 수 있는지 연구함
AST를 다양한 오디오 분류 벤치마크에서 평가했으며,
AudioSet에서는 0.485의 mAP, ESC-50에서는 95.6% 정확도, Speech Commands V2에서는 98.1% 정확도로 SOTA 달성
1. Introduction
비전 분야에서도 순수 attention 기반의 모델이 성공을 거둔 것에 영감을 받아 오디오 분류 task에서도 확인해보고자 함
AST, Audio Spectrogram Transformer
컨볼루션없이 동작하는 순수 attention 모델
오디오 스펙트로그램에 직접 적용되며 가장 낮은 층에서도 장기적인 전역 문맥을 포착 가능
mageNet에서 사전학습된 Vision Transformer의 지식을 AST로 전이 학습(transfer learning)하는 방식을 사용해 성능을 크게 향상
AST의 장점
- 우수한 성능
Audioset, ESC-50, Speech Commands를 포함한 다양한 오디오 분류 과제 및 데이터셋에서 평가
$\to$ SOTA 달성 - 가변 길이 입력 지원 및 범용성
테스크 별로 구조를 달리해야 하는 CNN 기반 모델과 달리
AST는 가변 길이 입력을 자연스럽게 지원하며, 아키텍처를 변경하지 않고도 다양한 태스크에 적용 - 단순한 구조와 빠른 수렴
SOTA CNN-어텐션 하이브리드 모델과 비교했을 때, AST는 더 단순한 아키텍처, 더 적은 파라미터 수, 더 빠른 학습 수렴 속도
AST와 ViT는 비슷한 구조를 가지지만, ViT는 고정된 차원의 input만 사용할 수 있음
2. Audio Spectrogram Transformer
2.1 Model Architecture

길이 t초의 입력 waveform은 25ms 해밍 원도우를 사용해 10ms마다 계산된 128차원의 log-Mel filterbank 특징 시퀀스로 변환
$\to$ 입력은 $128 \times 100t $크기의 스펙트로그램이 됨
이후, 스펙트로그램은 시간과 주파수 차원 모두에서 6씩 겹치게 하여 16×16 크기의 패치 N개로 나뉨
$N = 12 \times [(100t - 16) / 10 ] \to $ Transformer의 effective input sequence length가 됨
각각의 $16 \times 16$ 패치는 Linear Projection(패치 임베딩 계층)을 사용하여 768 차원의 1D 패치 임베딩으로 flatten됨
각 패치 임베딩에 learnable 위치 임베딩(768차원)을 추가
또한, 시퀀스의 맨 앞에 [CLS] 토큰을 추가
이렇게 만들어진 시퀀스가 Transformer의 입력으로 들어감
Transformer는 인코더와 디코더 층으로 구성되어 있지만, classification 작업을 위해 필요한 것이기 때문에 인코더만을 사용
💡 왜 인코더만 쓸까?
분류 작업에서는 디코더의 출력이 필요하지 않음
Transformer의 인코더는 변형없이 사용 $\to$ 전이 학습 적용에 유리
Transformer의 인코더는 임베딩 차원 768, 12개 층, 12개 헤드를 가지며 [CLS] 출력은 오디오 스펙트로그램 representation으로 사용됨
이후, sigmoid를 갖는 선형 계층이 이 representation을 분류를 위한 label로 매핑
2.2 ImageNet Pretraining
Transformer의 단점 중 하나는 CNN에 비해 더 많은 학습 데이터가 필요하다는 점
이미지 분류 작업에서 데이터 양이 1,400만 개 이상일 때에만 Transformer가 CNN보다 더 좋은 성능을 내기 시작
그러나 오디오 데이터셋은 일반적으로 그 정도의 대규모 데이터를 포함하지 않기 때문에, 오디오 스펙트로그램과 이미지가 유사한 형태를 갖고 있다는 점에 착안해, 우리는 AST에 교차 모달리티 전이 학습(cross-modality transfer learning)을 적용
Vision에서 Audio로의 전이 학습은 이전에도 연구된 바 있으며, 이들은 모두 CNN 기반 모델에 한정되어 있었음
구체적으로는 ImageNet에서 사전학습된 CNN 가중치를 오디오 분류용 CNN의 초기 가중치로 사용하는 방식
ViT와 AST는 구조적으로 유사 (예: 동일한 표준 Transformer 사용, 동일한 패치 크기, 동일한 임베딩 크기),
하지만 완전히 동일하지는 않기 때문에 전이를 위해 몇 가지 수정(adaptation)이 필요
- ViT의 입력은 3채널(RGB) 이미지인 반면, AST의 입력은 1채널 스펙트로그램
ViT 패치 임베딩 레이어의 3개 입력 채널에 해당하는 가중치들을 평균내어 하나의 채널 가중치로 만들고,
이를 AST의 패치 임베딩 레이어의 가중치로 사용
또한, 입력 오디오 스펙트로그램은 평균이 0, 표준편차가 0.5가 되도록 정규화 $\to$ 분포 일정하게 - AST의 입력은 오디오 스펙트로그램으로, 크기가 고정되지 않고 가변적
ViT의 입력은 일반적으로 고정된 크기(224×224 또는 384×384)
Transformer는 본질적으로 가변 길이 입력을 지원하므로 구조 전이는 가능하지만,
위치를 알 수는 없기 때문에 위치 임베딩(position embedding)은 주의해서 처리해야 함.
위치 임베딩은 ViT에서 학습한 공간 구조(24×24)에 맞춰져 있으므로,
→ AST에 맞게 크기를 잘라내거나(interpolate) 재구성(cut & interpolate) 해야 함.
cut and bi-linear interpolate
- 예를 들어, ViT는 384×384 크기 이미지를 입력으로 받고 16×16 패치 크기를 사용하므로, 총 패치 수는 24×24 = 576개입니다 (ViT는 패치 분할 시 겹침이 없음).
ViT 위치 임베딩 (24, 24, 768) - AST는 10초짜리 오디오 입력의 경우, 12×100 크기의 패치가 생성되며 각 패치에 위치 임베딩이 필요합니다.
AST 위치 임베딩 (12, 100, 768) - 따라서 우리는 ViT의 24×24 위치 임베딩 중 첫 번째 차원은 반을 자르고, 두 번째 차원은 선형 보간(interpolation) 하여(24개를 100개로 늘림) 12×100으로 변환하고 이를 AST의 위치 임베딩으로 사용합니다.
- [CLS] 토큰에 대한 위치 임베딩은 ViT에서 그대로 재사용
이러한 방식으로, 입력 형태가 달라도 사전학습된 ViT의 2D 공간 정보 학습을 AST로 전이할 수 있음
- 예를 들어, ViT는 384×384 크기 이미지를 입력으로 받고 16×16 패치 크기를 사용하므로, 총 패치 수는 24×24 = 576개입니다 (ViT는 패치 분할 시 겹침이 없음).
- 분류기 레이어 재구성
분류 작업 자체가 다르기 때문에, ViT의 마지막 분류기(classification layer)는 제거하고, AST를 위한 새로운 분류기 레이어를 초기화
본 연구에서는 ViT기반인 DeiT (Data-efficient image Transformer)의 사전학습 가중치를 사용
DeiT는 학습 시 [CLS] 토큰이 두 개 있는데, 우리는 이를 평균내어 하나의 [CLS] 토큰으로 만들어 오디오 학습에 사용
💡 왜 DeiT를 쓰냐면?
오디오 데이터셋은 이미지 데이터보다 훨씬 작고 희소하기 때문에, 원래 ViT처럼 많은 데이터를 요구하는 모델은 맞지 않음
3. Experiments
AudioSet을 타겟으로 실험하였으며, 추가로 ESC-50, SCV2의 실험도 진행
먼저, AudioSet은 Ensemble-S에서 사용한 모델 3개와 다른 patch split strategies을 사용한 모델 3개를 앙상블한 Ensemble-M에서 Balanced, Full 모두 최고 성능을 달성함

뿐만 아니라 수렴도 매우 빨랐음 (오직 5 epochs만 필요했다고 함)
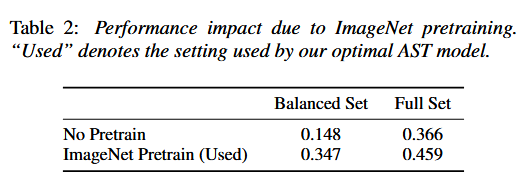
Pretrain 모델을 사용함으로써 성능이 훨씬 향상됨

ESC-50, SCV2도 당시 SOTA보다 훨씬 좋은 성능을 보여줌
'전공 > 딥러닝' 카테고리의 다른 글
| [DL] CNN 기반 모델 (LeNet/AlexNet/ZFNet/VGGNet/GoogLeNet/ResNet/ DenseNet/SENet/EfficientNet/ConvNeXt/MobileNet) (0) | 2025.03.21 |
|---|---|
| [DL] 오토인코더(Auto-Encoder)와 종류 (1) | 2025.02.06 |
| [DL] 다양한 Convolution 알아보기, Depthwise/Pointwise/Separable/Grouped/Deformable 등등 (1) | 2025.02.06 |
| [DL] 기울기 소실과 폭주 (Gradient Vanishing, Exploding) (1) | 2024.12.13 |
| [DL] 과적합과 규제 (Overfitting, Regularization) (1) | 2024.12.12 |



